128
Ansichten

Zuletzt aktualisiert am

Die Umwandlung von „Big Data“ in aussagekräftige Ergebnisse kann kompliziert erscheinen. Aber wenn Sie erst einmal verstanden haben, was es ist und wie es funktioniert, ist es nicht mehr so kompliziert, es sinnvoll zu machen.
Im Laufe der Jahre wurden viele Schlagworte in vielen Branchen in Mode. Es gibt nur wenige, die so beliebt und so lange wie Big Data geworden sind. Aber was genau ist Big Data?
Big Data bezieht sich auf einen virtuellen Ozean von Informationen aus verschiedenen Quellen, die analysiert und gefiltert werden, um aussagekräftige und umsetzbare Ergebnisse zu erzielen.
Der Prozess der Umwandlung von „Big Data“ in aussagekräftige Ergebnisse kann kompliziert und schwierig erscheinen. Wenn Sie jedoch erst einmal verstanden haben, was Big Data ist und wie es funktioniert, scheint es nicht so kompliziert zu sein, zu verstehen, wie es sinnvoll ist.
Wenn Sie Leute über "Big Data" sprechen hören, geschieht dies normalerweise mit viel Handbewegung und großen Worten. Wenn Sie jedoch die gesamte Übertreibung auf den Punkt bringen, sind die tatsächlichen „Daten“ tatsächlich viele mehrere Dateneingabeströme.
Um dies zu verstehen, kann ein Beispiel helfen. Nehmen wir an, Sie leiten eine Dachherstellerfirma. Ihre Marketingabteilung sucht nach einer Möglichkeit, besser vorherzusagen, wann die Marktnachfrage bald steigen wird.
Vor den Tagen von Big Data untersuchten Vermarkter Markttrends, verschickten Kundenumfragen und viele andere Aktivitäten.

Sie würden all diese Daten sammeln und in den internen Datenbanken ihres eigenen Unternehmens speichern. Möglicherweise ist jemand sogar dafür verantwortlich, die Marktforschungsdaten jährlich oder vierteljährlich zu aktualisieren.
Das Aufkommen von Big Data erweitert jedoch die Fähigkeit, diese Art von Forschung durchzuführen. Insbesondere Big Data ist besonders effektiv, um wichtige Trends oder Ereignisse nahezu in Echtzeit zu identifizieren.
Dateneingaben für diese Art der „Big Data“ -Analyse können Echtzeitdatenströme umfassen, indem Code geschrieben wird, der in die Anwendungsprogrammierschnittstelle (API) von vielen verschiedenen Unternehmen, die diese Daten veröffentlicht haben:
Um Big Data nutzen zu können, müsste das Marketing-Team dieses Unternehmens in einigen Fällen neue Technologien installieren.
Dies kann die Internet of Things (IoT) -Technologie bei Einzelhändlern umfassen, die das Verbraucherverhalten verfolgt und darüber berichtet. Oder es muss ein Programmierer den Code schreiben, der für die Schnittstelle mit der Twitter-API erforderlich ist, um alle Tweets herauszufiltern, in denen „Regenschirme“ oder der Firmenname erwähnt werden.
Jede dieser Technologien ist jetzt dank des Internets verfügbar. Über das Internet kann jeder Datenströme aus der ganzen Welt abrufen.
In diesem Fall kann das Setup in unserem Beispiel folgendermaßen funktionieren.
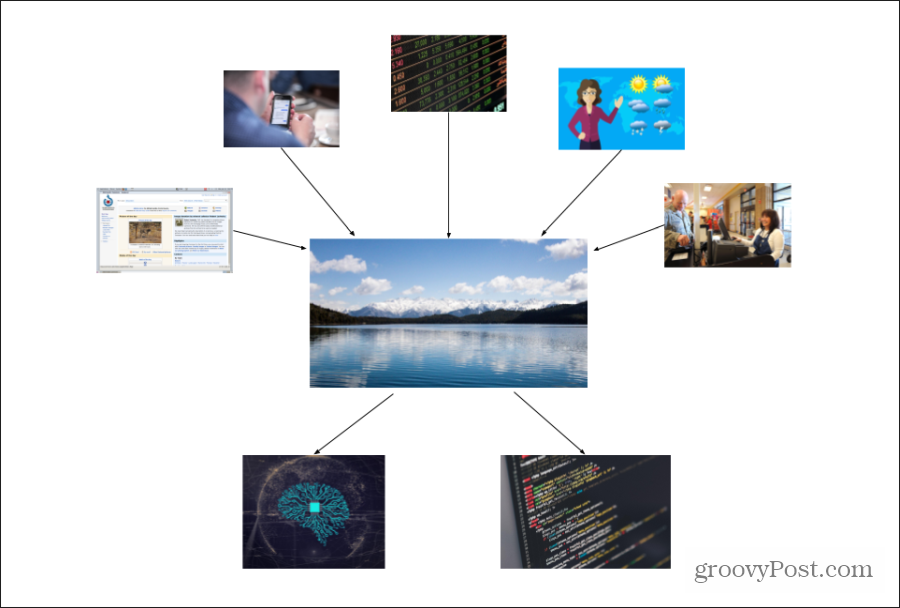
Dieses Diagramm zeigt, wie Daten aus vielen verschiedenen Quellen in den „Datensee“ des Unternehmens fließen. Die eingehenden Daten können unterschiedlich strukturiert sein, aber das Wichtigste ist, so viele Daten wie möglich aus allen Quellen zu sammeln.
Im Gegensatz zu einer Datenbank, die strukturierte Daten enthält, die in bestimmten Spalten und Zeilen organisiert sind, ist ein Datensee ein riesiges Repository für viele verschiedene Datenformen.
Die gespeicherten Daten können strukturiert oder unstrukturiert sein. Dies bedeutet, dass es möglicherweise strukturierte Zeilen und Spalten hat oder nicht. Die Daten können Zeichenfolgen sein, die eine bestimmte Formatierung verwenden, um Daten zu trennen. Jede Datenquelle kann Daten in beliebiger Form an einen Datensee senden.
Stellen Sie sich einen Datensee wie eine riesige Bibliothek vor, die viele Arten von Medien enthält, z. B. Bücher, Bilder auf Mikrofiche und Videos auf DVDs.

Stellen Sie sich den Ingenieur für digitale Intelligenz und Datenanalyse als Benutzer dieser Bibliothek vor. Diese Benutzer können Daten digital aus Büchern, Mikrofiche und DVDs abrufen und Wege finden, diese Daten zu mischen und zu kombinieren und daraus zu lernen, wie die Daten korrelieren.
Aus diesen Erkenntnissen entsteht tatsächliche, umsetzbare Intelligenz. Einige davon aus unserem Beispiel könnten sein:
All diese Erkenntnisse könnten das Marketingteam dazu veranlassen, geografisch in mehr Werbung zu investieren, wo die Nachfrage nach Dachverkäufen viel stärker ist. Die Produktionsbetriebe könnten ihre Produktionsanstrengungen auch auf jene Gebiete der Welt verlagern, in denen der Umsatz eher steigen wird.
Auf diese Weise kann jedes Unternehmen mithilfe von Big Data sein Marketing und seine Abläufe optimieren.
Die nächste Frage ist, wie Unternehmen so große Datenmengen verarbeiten und Trends erkennen.
Diese Art der Datenverarbeitung erfordert massive Computerressourcen. So sehr, dass Unternehmen große Großrechner nicht mehr wie früher vor Ort verwenden. Viele dieser Dienste werden jetzt aus der Cloud gekauft. Cloud Data Intelligence-Dienste wie Apache Hadoop bieten viele Computerknoten in einem großen Cloud-Netzwerk. Jeder dieser Knoten trägt zur Verarbeitungsleistung bei, die erforderlich ist, um massive Datenströme aus mehreren Quellen zu analysieren.

Diese Art von Rechenleistung ist das Herzstück der maschinellen oder digitalen Intelligenz und Datenanalyse. Hadoop ist das Software-Framework, mit dem dieses gesamte Netzwerk aus massiver Rechenleistung für Ingenieure der digitalen Intelligenz benötigt wird.
Sobald die Rechenmaschine verwertbare Informationen erzeugt, werden diese normalerweise in Form von Dashboards oder Berichten an das Unternehmen übermittelt.
Die Wahrheit ist, dass „Big Data“ mehr als nur Unternehmenssprache ist. Viele Unternehmen lernen, dass sie durch eine bessere Nutzung der Daten zahlreiche Erfolge erzielen können.
Während vieles, was Big Data in den letzten Jahren erreicht hat, für die Öffentlichkeit praktisch unsichtbar bleibt, hat Big Data tatsächlich einen erheblichen Einfluss auf den Alltag von Menschen auf der ganzen Welt.