0
Ansichten


Zuletzt aktualisiert am

Die Wayback-Maschine ist der beliebteste Teil der Internet-Archiv-Website. Mit dem kostenlosen Online-Tool, das erstmals im Jahr 2001 eingeführt wurde, können Sie „in die Vergangenheit reisen“, um zu sehen, wie Websites weltweit zu bestimmten Zeitpunkten aussahen. Die Wayback-Maschine verfügt über 562 Milliarde Webseiten zum Zeitpunkt dieses Schreibens, wobei jedes Jahr viele weitere hinzugefügt werden.
Hier ist ein Blick auf die Wayback-Maschine und was sie so besonders macht.
Das Internetarchiv wurde von Brewster Kahle und Bruce Gilliat gegründet und ist eine gemeinnützige Organisation mit der erklärten Mission „universeller Zugang zu allem Wissen“. Von Anfang an, Die Organisation hat der Öffentlichkeit freien Zugang zu digitalisierten Materialien wie Webseiten, Büchern, Audioaufnahmen, einschließlich Live-Konzerten, Videos, Bildern und Software, gewährt Programme.
Bis heute nimmt alles, was vom Internetarchiv gesammelt wird, mehr als 70 ein
Nur ein Teil des Internetarchivs, die Wayback-Maschine, wurde entwickelt, um geänderte oder entfernte Website-Inhalte zu erfassen. Seit dem Start ist es einer der beliebtesten und anerkanntesten Orte im Internet. Kahle und Gilliat benannten die Site nach dem fiktiven Zeitreisegerät in der Zeichentrickserie The Rocky and Bullwinkle Show aus den 1960er Jahren.
Obwohl das Internetarchiv die Website erst im Oktober 2001 der Öffentlichkeit zugänglich machte, begann die Wayback-Maschine ab Mai 1996 mit der Archivierung zwischengespeicherter Webseiten. Bis 2001 speicherten digitale Bänder Informationen, auf die nur ausgewählte Wissenschaftler und Forscher zugreifen konnten. Als alles fünf Jahre später (wie lange geplant) live ging, enthielt es bereits über 10 Milliarden archivierte Seiten.
Heute speichert die Site historische Webdaten auf einem Cluster von Linux-Knoten. Die Wayback-Maschine lädt alle öffentlich zugänglichen Informationen und Datendateien auf Webseiten über ihren Crawling-Mechanismus herunter. Hier ist jedoch nicht alles enthalten, was auf einer Website veröffentlicht wird, da einige Inhalte eingeschränkt oder in Datenbanken gespeichert sind, auf die nicht zugegriffen werden kann. Aus diesem Grund werden einige Websites besser gecrawlt als andere, je nachdem, wie Entwickler jeweils eine Website erstellt haben.
Sie werden auch feststellen, dass je neuer das Archiv ist, desto mehr Inhalte für eine bestimmte Website verfügbar sind. Ein neues Tool, das das Internetarchiv 2005 eingeführt hat, ist einer der Gründe, warum neuere Daten vollständiger sind. Archive-It.org hilft dabei, Inkonsistenzen bei teilweise zwischengespeicherten Websites zu überwinden, indem Institutionen und Ersteller von Inhalten die Sammlung und Aufbewahrung von Sammlungen digitaler Inhalte ermöglichen.
Webcrawler, manchmal auch als Spider oder Spiderbot bezeichnet, sind so alt wie das Internet. Diese Crawler sind Internet-Bots, die kontinuierlich zu Indexierungszwecken im Internet surfen und sie zu einem wichtigen Bestandteil jeder modernen Suchmaschine machen. Die Crawler, mit denen die Wayback-Maschine digitale Schnappschüsse von Websites erstellt, stammen aus verschiedenen Quellen, die sich im Laufe der Zeit geändert haben.
Wie Sie schnell feststellen werden, variiert die Häufigkeit von Schnappschussaufnahmen je nach Website erheblich. Je größer (und vielleicht beliebter) eine Website ist, desto häufiger wird in der Regel gecrawlt. Außerdem hängt vieles davon ab, wie oft eine Website Seitenänderungen aufweist. Selbst die kleinsten Websites werden schließlich gecrawlt, es sei denn, es gibt einen Grund, warum dies nicht der Fall ist. Beispielsweise werden kennwortgeschützte Websites nicht gecrawlt, und Websites, deren Websitebesitzer beantragt haben, dass sie nicht aufgenommen werden, werden ebenfalls nicht durchsucht.
Die Wayback Machine-Website ist für jedermann einfach zu bedienen. Geben Sie den Namen in die Suchmaschine der Website ein, um historische Schnappschüsse einer Website zu finden. Auf der Suchergebnisseite geben Hyperlinks Datum und Uhrzeit der Archivierung einer Website an. Klicken Sie auf den Link, um die Site "back in time" anzuzeigen.
In den folgenden Beispielen sehen Sie die Startseite der Apple-Website, die im Februar 2005 und November 2014 aufgezeichnet wurde, und die CNN-Homepage ab einem Datum im März 2004 und September 2010.
Hinweis: Diese Crawls enthalten auch Links zu anderen Seiten, die an den angegebenen Daten aufgezeichnet wurden, nicht nur zu den Startseiten.
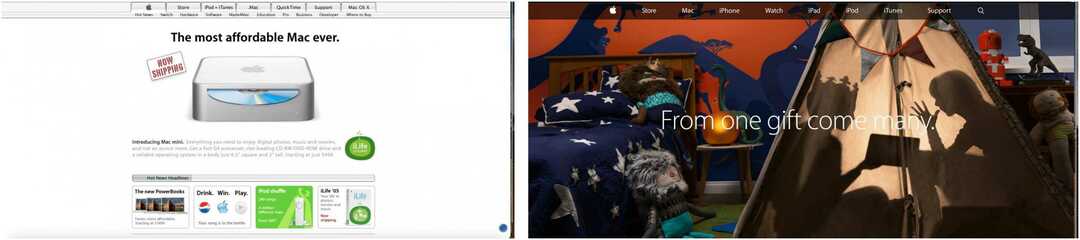
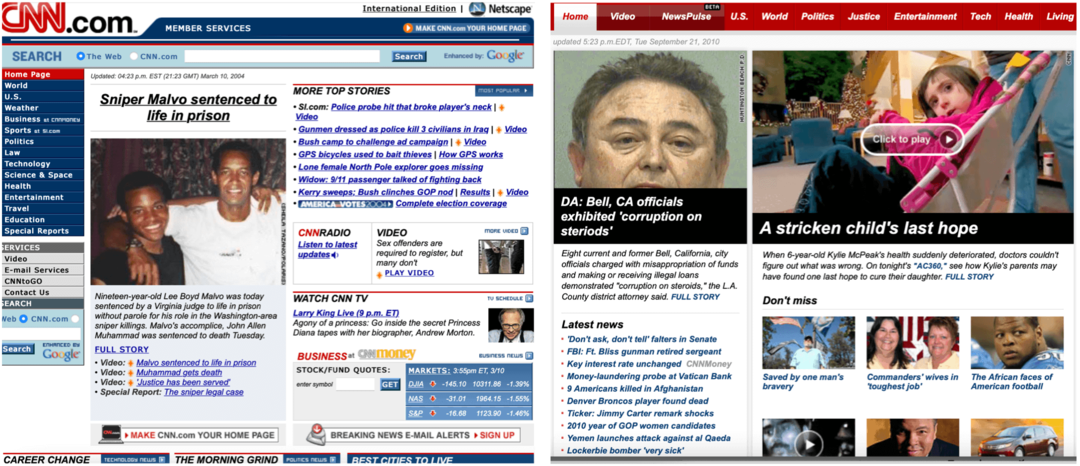
Die Wayback-Maschine wurde für Forscher und die Öffentlichkeit gleichermaßen entwickelt und verfügt über einige integrierte Tools, die Gelegenheitsbenutzer möglicherweise vermissen. Beispielsweise sind Suchergebnisseiten von Natur aus leicht zu referenzieren. Wie erläutert: „Wenn Sie eine archivierte Seite finden, auf die Sie auf Ihrer Webseite oder in einem Artikel verweisen möchten, können Sie die URL kopieren. Sie können sogar den Fuzzy-URL-Abgleich und die Datumsspezifikation verwenden... aber das ist etwas fortgeschrittener. "
Mit der Wayback-Maschine können Websitebesitzer auch die Funktion "Seite jetzt speichern" verwenden, um eine bestimmte Seite zu speichern. Und doch ist es nicht perfekt. Derzeit fügt die Funktion die Website-URL keinen zukünftigen Crawls hinzu. Außerdem speichert die Anfrage nicht mehr als eine Seite. Dies ist jedoch ein guter erster Schritt, um die Homepage Ihrer Website für die historischen Aufzeichnungen zu archivieren.
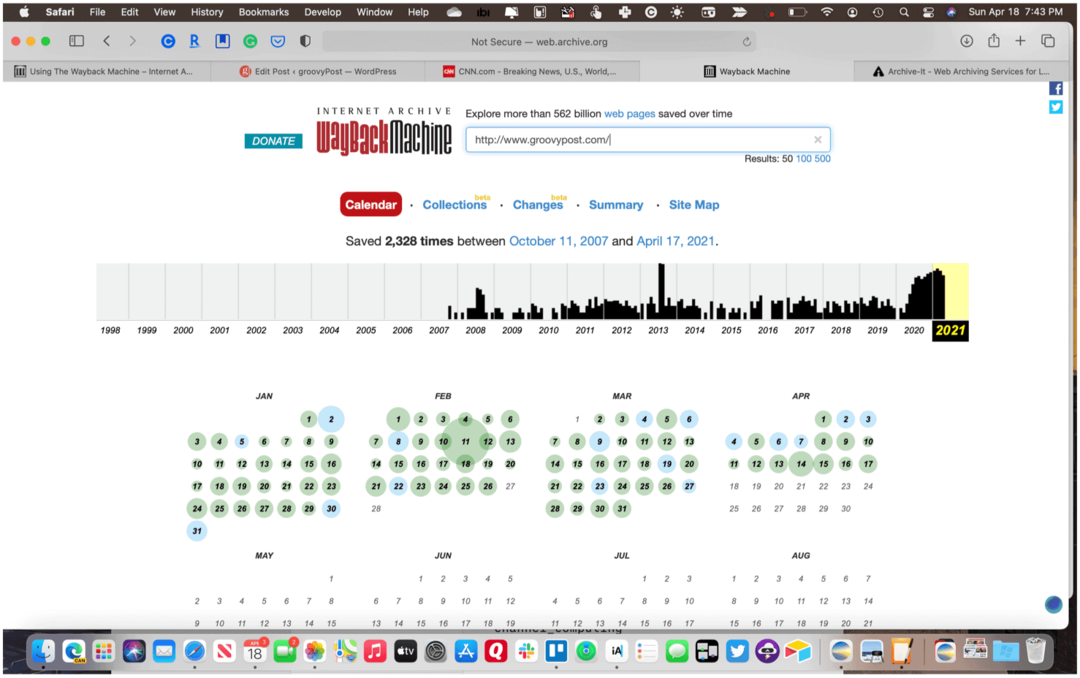
Sie müssen die Wayback-Maschine nicht jedes Mal besuchen, um eine neue Suche durchzuführen. Stattdessen können Sie Inhalte finden, indem Sie die Adresse in die Symbolleiste Ihres Webbrowsers eingeben. Verwenden Sie dieses Format für alle Suchvorgänge: http://web.archive.org/*/www.yoursite.com/*. Verwenden Sie zum Beispiel http://web.archive.org/*/www.groovypost.com/* um archivierte Seiten für den GroovyPost zu finden!
Schließlich befindet sich die Wayback-Maschine nicht nur über das Internet. Sie finden eine Wayback Machine App für iOS und Android. Es gibt auch Erweiterungen für Chrome, Safari und Firefox. Entwickler sollten auch die Internet Archive Wayback Machine-APIs überprüfen. Diese erleichtern Entwicklern das Abrufen von Informationen zu Wayback-Erfassungsdaten.
Die Internet Archive Wayback Machine unterstützt verschiedene APIs. Auf diese Weise können Entwickler leichter Informationen zu Wayback-Erfassungsdaten abrufen.
Die Zeitreise für Ihre Lieblingswebsites ist der Hauptgrund, die Wayback-Maschine zu besuchen. Es ist auch ein großartiges Tool für alle, die die Website-Geschichte für Schulprojekte oder geschäftliche Zwecke recherchieren. Was auch immer Sie tun, besuchen Sie die Wayback-Maschine und sehen Sie, was Sie in wenigen einfachen Schritten entdecken können.
Weitere Informationen zum Archive-It-Abonnementdienst des Internetarchivs finden Sie unter offizielle Website und fang noch heute an, einen Beitrag zu leisten!
